Overview
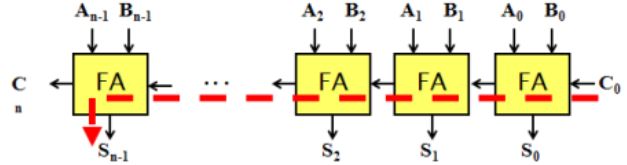
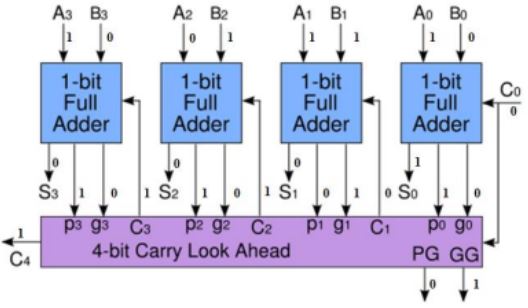
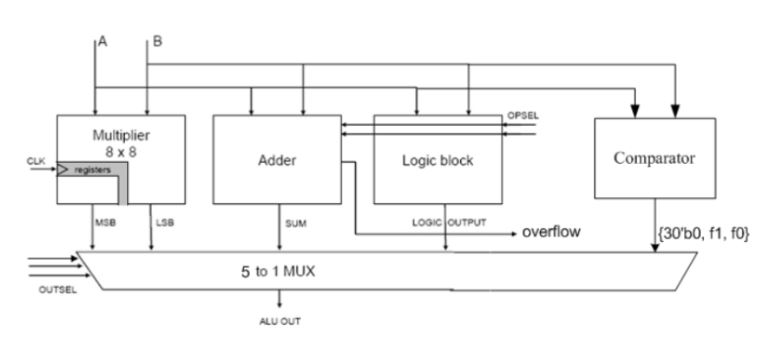
The purpose of this case study is to gain a further understanding of different 32-bit pipelined central processing unit (CPU) designs' performance; the comparison between different full-bit adders to showcase the delays, power consumption, and processing frequency of each design. Coupled with the concern of having a fast, high-performing CPU, a new arithmetic logic unit (ALU) architecture should be implemented and compared to the pre-existing full-adder designs. A pipelined CPU is capable of handling many instructions at once, and in this design, the CPU uses 32-bit length words, therefore the architecture for processing a plethora of computations in unison becomes critical in its front-end and back-end design optimization. The integration of the CPU is synchronized by an external clock and other signals to direct operations and operands for the ALU and instructions for addressing the memory file. Using the environments Cadence Virtuoso, Xcelium, Genus, and Innovus, along with the RTL design being written in Verilog HDL, allowed for the compilation, construction, and simulation of developing a high-performing, fast processing CPU.